
JDK, Java uygulamaları geliştirmek için gerekli tüm araçları bize sağlar. İçerisinde JVM, JRE, Java kütüphaneleri, Java Compiler ve Interpreter içerir. Bir java uygulaması geliştirmek için JDK yüklememiz yeterlidir çünkü diğer araçları JDK içirisinde barındırır.

Java kodlarının derlenerek byte kodlara dönüştürülmesi gerekir. Daha sonra bu byte kodlar JVM tarafından sistemin anlayacağı dile çevrilebilir. Java kodlarını byte koda çeviren mekanizmaya JRE denir. JRE içinde java kütüphanelerini ve JVM'yi barındırır.


JVM(Java Virtual Machine), Java dilinin en önemli özelliği olan bir kere yaz her yerde çalıştır mantığını sağlayan mekanizmadır. Java kodları hemen hemen tüm platformlar üzerinde çalışabilir. Java kodları .java uzantılı dosyalara yazılır. Daha sonra bu dosya compile edilerek byte koda dönüştürülür. Bu byte kodlar .class uzantılı dosyalara yazılır. Daha sonra bu byte kodlar JVM üzerinde çalıştırılır ve sistemin anlayacağı şekle dönüştürülür.
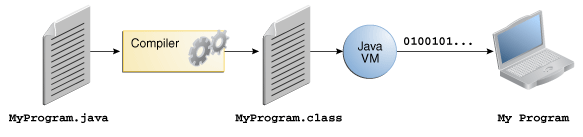
Yani JVM sistemin üzerinde çalışarak Java kodlarının her sistemde çalışabilmesini sağlar. Bunu yapabilmesi için her sisteme özel bir JVM olması gerekir. Sistemin Java kodu ile uygun bir şekilde çalışabilmesi için gerekli düzenlemeleri JVM yapar. Bizim yapmamız gereken tek şey Java kodunun çalışacağı makineye uygun JVM'yi yüklemek ve kodumuzu derlemektir.


Java JDBC kütüphanesi ile veritabanından kayıt silme işlemi. Connection nesnesi ile veritabanı bağlantısı oluşturulur. Statement nesnesi ile SQL cümlesi çalıştırılır.
package delete;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
public class DeleteExample {
public static void main(String[] args) {
try {
Class.forName("com.mysql.jdbc.Driver");
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/first_example","root","123456");
String deleteSQL = "DELETE FROM person WHERE id = ?";
PreparedStatement state = connection.prepareStatement(deleteSQL);
state.setInt(1, 1);
int result = state.executeUpdate();
if (result > 0) {
System.out.println("Successful");
} else {
System.out.println("Failed");
}
state.setInt(1, 2);
result = state.executeUpdate();
if (result > 0) {
System.out.println("Successful");
} else {
System.out.println("Failed");
}
state.close();
connection.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
Java JDBC kütüphanesi ile veritabanından kayıt çekme işlemi. Connection nesnesi ile veritabanı bağlantısı oluşturulur. Statement nesnesi ile SQL cümlesi çalıştırılır. ResultSet nesnesi ile dönen kayıtlara erişilir.
package select;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.Statement;
public class SelectExample {
public static void main(String[] args) {
try {
Class.forName("com.mysql.jdbc.Driver");
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/first_example","root","123456");
ResultSet result;
// SELECT With Dynamic Parameters
String selectSQL = "SELECT * FROM person WHERE id = ?";
PreparedStatement preparedState = connection.prepareStatement(selectSQL);
preparedState.setInt(1, 1);
result = preparedState.executeQuery();
if (result.next()) {
System.out.println(result.getInt("id") + " - "
+ result.getString("name") + " - "
+ result.getString("surname"));
}
System.out.println("-----------------------------------------------");
// SELECT With Static Parameters
Statement state = connection.createStatement();
result = state.executeQuery("SELECT * FROM person WHERE id = 1");
if (result.next()) {
System.out.println(result.getInt("id") + " - "
+ result.getString("name") + " - "
+ result.getString("surname"));
}
System.out.println("-----------------------------------------------");
// SELECT All Records
Statement stateAllRecords = connection.createStatement();
result = stateAllRecords.executeQuery("SELECT * FROM person");
while (result.next()) {
System.out.println(result.getInt("id") + " - "
+ result.getString("name") + " - "
+ result.getString("surname"));
}
preparedState.close();
connection.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
Java JDBC kütüphanesi ile veritabanındaki kayıtları güncelleme işlemi. Connection nesnesi ile veritabanı bağlantısı oluşturulur. Statement nesnesi ile SQL cümlesi çalıştırılır.
Github Linki
package update;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
public class UpdateExample {
public static void main(String[] args) {
try {
Class.forName("com.mysql.jdbc.Driver");
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/first_example","root","123456");
String updateSQL = "UPDATE person SET name = ? ,surname = ? WHERE id = ?";
PreparedStatement state = connection.prepareStatement(updateSQL);
state.setString(1, "Update");
state.setString(2, "Example");
state.setInt(3, 5);
int result = state.executeUpdate();
if (result > 0) {
System.out.println("Successful");
} else {
System.out.println("Failed");
}
state.close();
connection.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
Github Linki
package insert;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
public class InsertExample {
public static void main(String[] args) {
try {
Class.forName("com.mysql.jdbc.Driver");
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/first_example","root","123456");
String insertSQL = "INSERT INTO person (name,surname) VALUES (?,?)";
PreparedStatement state = connection.prepareStatement(insertSQL);
state.setString(1, "Berkay");
state.setString(2, "DEMİREL");
int result = state.executeUpdate();
if (result > 0) {
System.out.println("Successful");
} else {
System.out.println("Failed");
}
state.setString(1, "Insert");
state.setString(2, "Example");
result = state.executeUpdate();
if (result > 0) {
System.out.println("Successful");
} else {
System.out.println("Failed");
}
state.close();
connection.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
Statement nesneleri ile SQL ifadelerini veritabanına gönderebilir ve çalıştırabiliriz. Bu nesneler ile parametre geçişi de yapabiliriz. Ayrıca bu nesneler bir veritabanında kullanılan Java ve SQL veri türleri arasındaki veri türü farklılıklarını köprülemeye yardımcı olan yöntemleri de tanımlarlar.
Statement Nesneleri
- Statement: Statik SQL sorgularını çalıştırmak için kullanılır. Dinamik parametre geçişi yoktur. Bir sorgu çok defa çalıştırılmayacaksa kullanılması mantıklıdır.
- PreparedStatement: Dinamik SQL sorgularını çalıştırmak için kullanılır. Yani sql sorgularımıza parametre geçişi yapabiliriz. Bir sorgu çok defa çalıştırılcaksa kullanılması mantıklıdır. Çünkü Statement nesnesi ile sorgu her çalıştırıldığında derlenirken PreparedStatement nesnesi sorguyu tek bir kez derler.
- CallableStatement: Veritabanına kaydedilmiş prosedürleri çalıştırmak için kullanılır. Ayrıca dinamik parametreleri kabul eder.
Bir SQL deyimini yürütmek için bir Statement nesnesini kullanmadan önce, aşağıdaki örnekte olduğu gibi, Connection nesnesinin createStatement() yöntemini kullanarak bir tane oluşturmanız gerekir.
Statement stmt = null;
try {
stmt = conn.createStatement( );
. . .
}
catch (SQLException e) {
. . .
}
finally {
. . .
}
Bir Statement nesnesini oluşturduktan sonra, bunu bir SQL ifadesini yürütmek için üç yürütme yönteminden biriyle kullanabilirsiniz.
- boolean execute (String SQL): Bir ResultSet nesnesi alınabiliyorsa true, aksi takdirde false değerini döndürür. Dinamik SQL kullanmanız gerektiğinde bu yöntemi kullanılabilir.
- int executeUpdate (String SQL): SQL ifadesinin yürütülmesinden etkilenen satır sayısını döndürür. Bir INSERT, UPDATE veya DELETE ifadesi gibi etkilenen çok sayıda satır almayı beklediğiniz SQL ifadelerini çalıştırmak için bu yöntemi kullanabiliriz.
- ResultSet executeQuery (String SQL): Bir ResultSet nesnesi döndürür. Bir SELECT deyiminde olduğu gibi bir sonuç kümesi elde etmeyi beklediğimiz durumlarda kullanabiliriz.
PreparedStatement pstmt = null;
try {
String SQL = "Update Employees SET age = ? WHERE id = ?";
pstmt = conn.prepareStatement(SQL);
. . .
}
catch (SQLException e) {
. . .
}
finally {
. . .
}

JDBC (Java Database Connectivity), Java programlama dili ile veritabanları (Mysql, Oracle, MSSQL, vs.) arasında bağlantı kurulmasını ve çeşitli işlemlerin yapılmasını sağlayan bir Java kütüphanesidir.
JDBC kütüphanesi ile aşağıdaki veritabanı işlemleri yapılabilir;
- Veritabanı bağlansının yapılması.
- SQL deyimleri oluşturulması
- Veritabanında SQL sorgularının çalıştırılması.
- Elde edilen kayıtları görüntülemesi ve değiştirilmesi.
- JDBC API: Uygulama ile JDBC Yöneticisi bağlantısını sağlar.
- JDBC Driver API: JDBC Yöneticisi ile Sürücü Bağlantısını destekler. Aşağıdaki mimari diyagram, JDBC sürücüleri ve Java uygulaması ile ilgili sürücü yöneticisinin yerini göstermektedir.

JDBC API, aşağıdaki arayüzleri ve sınıfları sağlar;
- DriverManager: Bu sınıf, veritabanı sürücülerinin bir listesini yönetir. Java uygulamasından gelen bağlantı istekleri ile uygun veritabanı sürücüsünü eşleştirir ve bağlantı oluşturur.
- Driver: Bu arayüz veritabanı sunucusuyla olan iletişimi idare eder. Nadiren bu nesne kullanılır. Genellikle bu nesneyi yöneten DriverManager nesnesi üzerinden erişim yapılır.
- Connection: Bu arayüz, bir veritabanıyla iletişim kurmak için tüm yöntemleri içerir. Connection nesnesi iletişim bağlamını temsil eder, yani veritabanıyla yapılan tüm iletişim yalnızca bağlantı nesnesi aracılığıyla yapılır.
- Statement: Bu arayüz ile SQL ifadelerini veritabanına gönderilir ve çalıştırılır. Ayrıca bu sınıftan türemiş alt sınıflar ile parametre geçişide yapılabilir.
- ResultSet: Bu nesneler, SQL sorgusu çalıştırıldıktan sonra veritabanından alınan verileri tutar. Verilerin arasında dolaşmanıza izin vermek için bir işaretçi görevi görür.
- SQLException: Bu sınıf, bir veritabanı uygulamasında meydana gelen hataları yönetir.
Örnek JDBC Kodları

İlişkisel veritabanlarında yaptığımız bazı işlemlerde(select, update, delete vs.) ilgilendiğimiz verinin disk üzerinde aranması ciddi bir sorundur. Örneğin 1 milyon satırın olduğu bir hesaplar tablosunda bir kişinin hesabındaki parayı güncelleyeceksiniz. Bu işlem bir banka uygulamasında çok sık yapılan bir işlemdir. Bu işlemi yapmak için önce veritabanı sisteminin hesabı güncellenecek kişiyi bulması daha sonra o kişinin hesabındaki parayı güncellemesi gerekir. Bu tablodaki 1 milyon kaydın içerisinde ilgilendiğimiz verinin bulunması ciddi bir problemdir. Çünkü normal yöntem ile tüm kayıtların tek tek okunması ve bizim sorgumuz ile karşılaştırılması gerekir. Bu işlem bir milyon satır olan bir veritabanında çok uzun sürecektir ve bu bizim istemediğimiz bir şeydir. Bu problemi ortadan kaldırmak için index denilen yapı kullanılır. İndex'ler arama yapılacak kolonlar üzerine kurulur. Daha sonra arama işlemi sadece bu kolonlar üzerinde olur. Bu şekilde arama işleminde ilgilendiğimiz veri boyutunda ciddi bir şekilde azalma olur. Ayrıca geliştirilen çeşitli index türleri ile arama işlemlerinde çeşitli yöntemler kullanılarak bu işlem çok daha kısa sürelerde yapılabilir hale gelmiştir. Genellikle index yapıları her satırı tek başına ifade edebilen primary key'ler üzerine kurulur. Bu şekilde yapılması ve daha sonra bu primary key üzerinde arama yapılması en iyi yöntemdir. Bu konuda bilinmesi gereken bir diğer önemli bilgi ise index'lere sadece select işlemlerinde ihtiyaç duyulmadığıdır. Örneğin bir kaydı güncellemek veya silmek istediğinizde de öncelikle o kaydın bulunması gerekmektedir. Bu yüzden index veritabanlarında yapılan bir çok işlemi ciddi şekilde hızlandırmaktadır. Index'ler ikiye ayrılırlar. Eğer veriler fiziksel olarak sıralanıyor ise Clustered, fiziksel değil ise Non-Clustered index’tir.
Clustered Index (Kümelenmiş)
Verileri fiziksel ve alfabetik olarak sıralar. (Örn : Telefon rehberi) Bu tip indexler B-Tree yapısına sahiptir. Verilerin oluştuğu sayfalara pointer(işaretleyici) kullanarak gitmesine gerek kalmadan verinin direk yerine ulaşabilir. Kümelenmiş bir index kullanıldığında ulaşılan yer verinin kendisidir. Eğer tabloda Primary Key (Birincil anahtar) var ise bu kümelenmiş index yapısına sahiptir. Her tabloda en fazla bir tane bulunabilir. Clustered Index yapılan kolon artan veya azalan bir değere sahip olmalıdır.
Non-Clustered Index
Index oluşturuğumuz verilerin ayrıca sıralandığı ve bu veriler üzerinde arama yapılan index türüdür. Index üzerinde arama yapıldıktan sonra bulunan verinin bellekteki fiziksel yerine gitmek için pointer'lar kullanılır. Bu index türünden tablomuzda çok sayıda olabilir. Örnek verecek olursak bir kitabın içindekiler kısmını kullanarak çok daha hızlı bir şekilde aradığımız sayfayı bulabiliriz. Burada yapılan kitabın içindeki başlıklar üzerinde bir index oluşturmaktır. Daha sonra pointer(sayfa numarası) ile o başlığın gerçekte bulunduğu sayfaya çok kolay bir şekilde gidebiliriz.
Index Nasıl Tanımlanır?
CREATE INDEX index_adi ON tablo_adi(kolon_adlari)
CREATE UNIQUE INDEX index_adi ON tablo_adi(kolon_adlari)
Not! Unique index tanımladığımızda index tanımlanan her verinin bir tane olması gerekir.
Index Nasıl Silinir?
DROP INDEX index_adi
NOSQL, yıllardır kullanılan ilişkisel veritabanlarına alternatif olarak ortaya çıkmış bir veritabanı sistemidir. Günümüzde verilerin boyutlarının çok fazla artışından ve big data denilen kavramın ortaya çıkışından sonra artık ilişkisel veritabanları ihtiyaçları tam anlamıyla karşılamamaya başlamıştır. Bu yüzden NOSQL veritabanları ilişkisel veritabanlarına bu anlamda bir alternatif üretmek için ortaya çıkmıştır. NOSQL sistemlerinde SQL dili kullanılmadığı için NOSQL olarak adlandırılmıştır.
NOSQL'in önemini şöyle vurgulayabiliriz. Google yıllardır indekslediği sitelerin bilgilerini ilişkisel veritabanında(RDBMS) değil Big Table üzerinde tutuyor. Bu sayede RDBMS gibi büyük verileri performanslı bir şekilde işleyemeyen pahalı sistemler yerine açık kaynaklı ucuz ve performanslı sistemleri tercih ediyor.
NOSQL, RDBMS gibi işlem tabanlı çalışmaz. Bunun yerine yatay büyüme yaparak, performans kazancı sağlar. Verileri bölerek kopyalarını dağınık sistemin farklı parçalarına ekler böylelikle tutarlılık sağlar ve her bir parça için harcanan yük azaltılmış olur.
RDBMS önceden tasarlanıp sütunları belirlenir ve satır satır eklenir. Ancak NOSQL de bu tip bir tanıma gerek yoktur. Bunun yerine daha esnek bir yapı bulunur. Bu kafanızda soru işareti bırakıyorsa şöyle düşünün. 2 adet kolonu olan bir tablonuzda integer verileri tutuyorsunuz yeni satırınızda bunlar yerine varchar eklemeniz gerekiyor. Hiçbir değişikliğe gerek kalmadan verinizi ekleyebilirsiniz. A kolonu B kolonu varken C ve D'ye gerek yok.
NOSQL birincil indeks değerine ihtiyaç duyar ve bunun üzerinden erişim sağlar. RDBMS de bu zorunlu değildir. Oluşan indeks üzerinden belirli aralığa hızlıca ulaşılabilir.
RDBMS bir sistem kullanırken verinin nasıl depolanacağınız ile ilgilenirken, NOSQL için depoladığınız veriyi nasıl kullanacağınızı düşünüyorsunuz.
NOSQL Türleri
- Döküman (Document) tabanlı: Bu tip veri tabanları JSON yapısında kayıt yapar. Bu yapılarda sınırsız alan oluşturabilirsiniz. Hatta sınırsız alanların içine sınırsız alanlar ve onların da içine şeklinde devam edebilirsiniz. MongoDB, CouchDB, Amazon Simple DB, Cassandra, HBase...
- Anahtar / Değer (Key / Value) tabanlı: Bu sistemlerde anahtarlara karşılık gelen tek bir bilgi bulunur. Kolon yapısı yoktur. MemcacheDB, Berkeley DB, Azure Table Storage...
- Grafik (Graph) tabanlı: Bu sistemler diğerlerinden farklı olarak verilerin ilişkisini saklayan Graph Theory modelindeki sistemlerdir. Neo4J, FlockDB...
OLTP ve OLAP, veri depolama sistemleridir. Bu iki sistemde günümüzde kullanılır ve iki sisteminde birbirine göre avantajları ve dezavantajları vardır. Bu iki sistemin kullanıcı kitlesi ve amacı birbirinden farklıdır. OLTP'nin genel amacı veriyi daha verimli tutmaktır. OLAP ise veri üzerinden karar vermeye yöneliktir. OLAP iş dünyasında oluşan ihtiyaçlar üzerine ortaya çıkmış bir veri depolama sistemidir. Bu iki sistemin özellikleri;
OLTP
Temel Amacı : Veriyi daha verimli tutmak
Kullanıcılar : IT Çalışanları, SQL dilini bilen kişiler
Fonksiyonlar : Günlük işler, Belli kategorilere göre veriler
DB Tasarımı : İlişkisel tasarım
Veri : Anlık veriler
Kullanım : Tekrarlı işlemler kullanılır.
İşlemler : Okuma/Yazma/Güncelleme vs.
İşlemlerin Boyutu : Basit sorgular
İşlem Çıktıları : Onlarca, yüzlerce satır
Veritabanı Boyutu : 100MB - 100GB
OLAP
Temel Amacı : Veri üzerinden çıkarım yapmak
Kullanıcılar : Bilgi ile uğraşan tüm kişiler.
Fonksiyonlar : Karar vermeye yönelik veriler
DB Tasarımı : Konuya yönelik tasarım
Veri : Tüm veriler üzerinden veri çıkarımı
Kullanım : Genellikle özel işlemler kullanılır. (Konuya özel veri çıkarımı)
İşlemler : Okuma ağırlıklı
İşlem Boyutu : Karmaşık sorgular
İşlem Çıktıları : Milyonlarca satır
Veritabanı Boyutu : 100GB - 100TB
OLTP (Online Transactional Processing), sistemler genellikle ilişkisel veri tabanları üzerine kurulmuş, üzerinde sürekli işlem yapılan veritabanı sistemleridir. Adından da anlaşılacağı gibi çok fazla transactional işlemler içeren yani insert, update, delete şeklide DML (Data Manipulation Language) işlemleri içeren veri depolama sistemleridir. OLTP sistemlerde sürekli yoğun işlemler yapılır. Sağlam bir ilişkisel yapı üzerine kurulmuştur, günlük hayatta kullanılan sistemlerin çoğu OLTP ürüne kurulu sistemlerdir.
OLTP sistemler geçmişe yönelik, birden fazla boyutta rapor oluşturmada, farklı bakış açılarında analiz yapmada zorlanırlar. Bu nedenle raporlama sistemlerinde OLAP tercih edilir.
OLTP sistemlerde sorgulama dili olarak TSQL kullanılırken, OLAP sistemlerinde MDX (MultiDimensional Expression) dili kullanılır.
Özellikler
Veriler üzerinde uğraşan kişilerden bir uzmanlık (SQL) bekler.
Verinin daha verimli nasıl tutulacağı ile ilgilenir.
Karar vermeyi desteklemez.
İlişkisel veritabanları üzerinde çalışır.
Veri odaklıdır.
Genellikle bilgisayar bilimi ile uğraşan kişiler tarafından kullanılır.
Çoklu kullanıcı desteği sağlar.
Veri kaynağı üzerinde karar vermeye yardımcı olacak şekilde yapılan veri analizi ve sorgulama islemlerine OLAP denir. OLAP, klasik veritabanlarının karar verme işleminde işlevsel olamamasından ve verilere erişim konusunda bir uzmanlık gerektirdiğinden dolayı ortaya çıkmıştır. Klasik veritabanları verinin daha verimli nasıl tutulacağı ile ilgilenilirken, OLAP veriler üzerinde nasıl daha iyi çıkarımlar yapılabileceği ile ilgilenir. Bu yüzden OLAP ile tutulan veriler çok boyutludur. Ayrıca klasik veritabanlarından istediğimiz verilere erişmek için SQL'e hakim olmamız gerekir. İş dünyasında verilere yöneticiler, karar vericiler ve analistler erişmek istediklerinden dolayı bu büyük bir problemdir. OLAP ile bu problem aşılmıştır ve verilere erişmek isteyen kişilerden SQL gibi bir uzmanlık beklenmez. OLAP analitik islemler için tasarlanmış, çok boyutlu ve özet bilgilerin tutulduğu veritabanlarıdır. Burada Analitik işlemlerden kasıt ise OLTP (klasik veritabanı yaklaşımı) sistemlerinde tutulan verilerin belli kriterlere göre gruplanması ve saklanması islemidir. OLAP sistemlerin en önemli özelliklerinden bir tanesi verilerin zaman boyutlu olmasıdır. Yıldız, kar tanesi, galaksi modeli gibi çeşitleri vardır.
Özellikler
- Veriler üzerinde uğraşan kişilerden SQL gibi bir uzmanlık beklemez.
- Verinin nasıl tutulacağı ile değil veri ile doğrudan ilgilenir.
- Karar vermeyi destekler.
- Veri ambarı veya özel veritabanları üzerinde çalışır.
- Özel amaçlı, çok boyutlu, geniş odaklı sorgular ve raporlamalar için kullanılır.
- Konu odaklıdır.
- Karar vericiler, yöneticiler ve analistler tarafından kullanılır.
- Seffaflık, erişilebilirlik, her şarta uygun boyutlandırılabilirlik sunar.
- Sınırsız sekilde çarpraz raporlama olanağı sağlar.
- Çoklu kullanıcı desteği sağlar.
- Esnek raporlama özelliği sunar.
- Boyut ve gruplamalarda sınırı yoktur.
OLAP TİPLERİ
- Çok Boyutlu OLAP (MOLAP): Klasik OLAP formudur. Küçük veri setleri için uygundur.
- İlişkisel OLAP (ROLAP): İlişkisel veri tabanlarıyla çalışan olap tipidir. Temel veri ve boyut tabloları, ilişkisel tablolar olarak depolanır ve yeni tablolar toplu bilgiyi tutmak için oluşturulur. ROLAP daha ölçeklenebilirdir, fakat yüksek hacimli işlemlerin etkili kurulumu zordur.
- Hibrid OLAP (HOLAP): Performans olarak MOLAP ile ROLAP arasındadır.Açık bir tanımı olmamakla birlikte, veriyi ilişkisel ve özel depo olarak bölen OLAP tipidir denilebilir. Örneğin bir HOLAP veritabanı, yüksek miktarda detaylı veri için ilişkisel tablolarını, daha detaysız ve düşük miktarda veri için özel depoları kullanabilir.
İlişkisel veritabanı teorisinde geçen ve ilişkisel bir veri tabanının hafızayı daha verimli kullanması için geliştirilen normal şekiller vardır. 1NF, 2NF, 3NF, BCNF ve 4NF olan bu normalizasyon yöntemlerinin hepsini sırayla uyguladığımızda tuttuğumuz veriler hafızayı olabildiğince en iyi şekilde kullanır. Ancak bu durumda hız konusunda ciddi kayıplar yaşayabiliriz. Bu gibi durumlarda denormalization denilen yöntem ile normalizasyon yapmak için veritabanı tasarımında kullanılan kuralların dışına çıkarak veritabanını tekrar tasarlayabiliriz. Aynı şekilde bazı durumlarda da tüm normal formlara uygun hale getirmek yerine istediğimiz seviyeye kadar olan normal formları uygulayarak veritabanı tasarımını yapabiliriz. Örnek verecek olursak tüm normal formları sağlayan bir veritabanı tasarımı yaptık ve çok sık erişilen veri kümesine erişmek için ondan fazla tabloyu birleştirmemiz(join) gerekiyor. Bu durum hem hız hem de kullanılabilirlik açısından sıkıntılar yaratabileceğinden en makul seviyede normal form uygulamak genellikle veritabanı konusunda yapılması gerekendir. Genellikle veritabanı tasarımlarında BCNF'a kadar kurallara uyacak şekilde tasarım yapılır.
İlişkisel veritabanı teorisinde geçen ve ilişkisel bir veri tabanının hafızayı daha verimli kullanması için geliştirilen normal şekillerden beşincisidir. Bir veri tabanı tasarlanırken veya daha sonradan normalleştirilebilir yani normal form kurallarına uyması sağlanabilir. Bu sayede veritabanının daha az yer kaplaması sağlanmış olur. Ancak bazı durumlarda yerden fedakarlık yapılarak hız ön plana çıkar. Bu durumda normalleştirilmiş bir veritabanının bozulması (denormalization) gerekir. Veritabanımızın dördüncü normal şekle uyması için iki temel kural vardır;
- BCNF'a uymalıdır.
- Çok-değerli bağımlılıkları (Multli-Valued dependency) olmamalıdır.
İlişkisel veritabanı teorisinde geçen ve ilişkisel bir veri tabanının hafızayı daha verimli kullanması için geliştirilen normal şekillerden dördüncüsüdür. Bu şekle genelde 3.5NF'de denir. Bir veri tabanı tasarlanırken veya daha sonradan normalleştirilebilir yani normal form kurallarına uyması sağlanabilir. Bu sayede veritabanının daha az yer kaplaması sağlanmış olur. Ancak bazı durumlarda yerden fedakarlık yapılarak hız ön plana çıkar. Bu durumda normalleştirilmiş bir veritabanının bozulması (denormalization) gerekir. Veritabanımızın boyce codd normal form'a uyması için iki temel kural vardır;
- Üçüncü normal şekle uymalıdır.
- Bir tablodaki anahtarın tanımladığı tüm kolonlar bir aday anahtar (candidate key) olmalıdır.